I’m not sure how one returns to blogging after a two-year hiatus. Probably it should be with something more substantial than this post, which is about regularization in statistics and how I came to understand it. (This account comes from Vapnik’s Nature of Statistical Learning Theory, which I should have finished by now but I keep getting distracted by “classes” and “research” and also “television” and “movies.”)
One of the most basic questions I had when initially learning statistics was: Why do we need to regularize least-squares regression? The answer, I was told, was to prevent overfitting. But this wasn’t totally satisfactory; in particular, I never learned why overfitting is a phenomenon that should be expected to occur, or why ridge regression solves it.
The answer, it turns out, is right there on the Wikipedia page. Speaking very generally: we have some data, say 

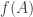


Now we want this functional to have the property that if the data of the response variable 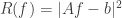
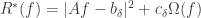
I also learned — though not from Vapnik — that you can derive ridge regression by putting a normal prior on the parameters in your model and then doing standard Bayesian things. But this doesn’t really explain why overfitting is a problem in the way the above account does — at least I don’t think so.
Question: Is there a natural correspondence between well-posed problems and “good” prior distributions on the parameters? (Meta-question: Is there a way to make that question more precise?)
(The title of this post is a Simpsons reference. Some things never change.)
