So in the last post, we defined the discrete Fourier transform and gave some of its basic properties. At the end, we claimed that it gives us a simple notion of pseudorandomness that allows us to make rigorous the intuition that “pseudorandom subsets of 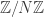
Posts Tagged ‘roth’s theorem’
GILA 4: The pseudorandom case
September 19, 2009GILA 3: The Fourier transform, and why it works
September 3, 2009At the end of the last post, we outlined an approach to proving Roth’s theorem via a density-increment method. I’ll re-post it here, a little more fleshed out, for convenience.
Sketch. The idea is to deal with “structured sets” (like sets that are themselves long arithmetic progressions) and “pseudo-random sets” in different ways; we saw last time that the density-increment argument looks promising for structured sets, but “random” sets won’t succumb to it.
First, we need to make rigorous our intuition that “random enough” sets of positive density will have length-3 APs. The obvious way to do this is by showing the contrapositive. We want to find some suitable “randomness measure” such that random dense sets have high randomness measure. Now let
be a positive-density set without 3-APs; we want to show that this condition is enough to guarantee that
has low randomness measure.
Now for our modified-probabilistic argument. We want to show that “low-randomness” sets can’t be uniformly distributed (mod d) for every d; this guarantees the existence of an AP on which it has higher density. We pass to this AP; rinse, lather, and repeat, until our density rises above some pre-set bound (
will do nicely.) We also want to introduce a tool that tells us how much a set “looks like” an arithmetic progression with common difference d; this is because we need to obtain quantitative bounds for the density-increment argument, in order to ensure that the densities of our set on the sequence of APs don’t monotonically approach, say, 0.0000001.
So we’re looking for two technical tools; one that quantifies the “randomness” of a set, and one that lets us correlate our set with a candidate arithmetic progression to pass to so that our density-increment argument will actually work quantitatively. As it turns out, though, we can find one tool that will do both jobs for us; the discrete Fourier transform.
GILA 2: The probabilistic approach
August 27, 2009To begin, a historical curiosity. In the last post, I talked about Khinchin’s little book on number theory, which from today’s perspective is one of the earliest books to deal entirely with additive combinatorics and additive number theory. One of Khinchin’s most famous results has to do with the denominators of continued fractions; Khinchin’s original proof of the theorem was quite complicated and involved. Nowadays, the existence of Khinchin’s constant is understood as a simple consequence of the ergodicity of the Gauss-Kuzmin-Wirsing operator.
Where else do we see ergodic theory popping up to simplify complicated proofs? Why, in additive combinatorics! Although we won’t discuss it in this series, ergodic theory has become a central tool for Szemeredi-type theorems, and some results are still only provable by such methods (for instance, until recently, the density Hales-Jewett theorem was in this class.)
To top it all off, note that ergodic theory was originally motivated by problems in statistical physics. Guess who wrote one of the best-known textbooks on mathematical statistical physics? But on to the math!
We’ve seen that traditional arguments based on the pigeonhole principle and such aren’t sufficient to prove Roth’s theorem. So we’ll go to the next tool in our kit — the probabilistic method.
The probabilistic method is one of the most useful weapons in a combinatorialist’s arsenal, even having a whole textbook devoted to it. (The linked page is out of date; a third edition was published last year.) The core of the method is this — if we want to show the existence of an object with a given property, instead of constructing one directly, we instead show that a randomly chosen large enough object has the property with positive probability. Its best-known use in Ramsey theory is for proving lower bounds, where it often gives the best known results, but clever applications can give upper bounds as well, for instance in the proof of Kraft’s inequality. Of particular interest to us is the fact that it provides our first nontrivial proof in the direction of Roth’s theorem.
GILA 1: van der Waerden and all that
August 22, 2009I’m beginning my GILA series announced on Thursday with a short exposition of van der Waerden’s theorem, and an attempt to extend its proof to the density version (at least in the k=3 case). Before I start, I should mention something I neglected in the last post: that this series is as much for my benefit as for that of any “interested lay audience” out there. Someone like Terry Tao could undoubtedly do a better series of this type (and, indeed, I’ll be leaning heavily on my borrowed copy of Tao and Van Vu’s Additive Combinatorics throughout) but they haven’t, so I’ll try. However, there are certain to be a number of embarrassing mistakes, unjustified statements, lines of thinking left unresolved, etc., throughout (indeed, an anonymous commenter noted two in the introductory post!), and I encourage readers to point them out in the comments.
So, on to van der Waerden’s theorem. van der Waerden’s theorem is one of the early jewels of Ramsey theory (actually predating Ramsey’s article by a couple of years) and can be viewed as a weaker version of Szemeredi’s theorem. It states simply that, for any integers 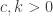
Khinchin, in his wonderful book which unfortunately appears to be out of print (at least in English), gives some history of the problem:
All to whom this question [the theorem in the c = 2 case] was put regarded the problem at first sight as quite simple; its solution in the affirmative appeared to be almost self-evident. The first attempts to solve it, however, led to nought… [T]his problem, provoking in its resistance, soon became the object of general mathematical interest… I made [van der Waerden’s] acquaintance, and learned the solution from him personally. It was elementary, but not simple by any means. The problem turned out to be deep; the appearance of simplicity was deceptive.
This last clause is particularly wonderful, describing as it does not only van der Waerden’s theorem but Ramsey theory and perhaps even combinatorics in general.
The usual proof (given in story-form by Zeilberger here) is not van der Waerden’s, however, but comes from Khinchin, attributed by him to a M.A. Lukomskaya in Minsk. It is a masterpiece, using nothing but a very clever inductive argument and some application of the pigeonhole principle. For the sake of self-containedness, I’ll sketch the argument below the fold.
GILA 0: Roth’s proof of Roth’s theorem
August 20, 2009I’m returning from my unplanned, unannounced hiatus from blogging with a series on the standard (Fourier-theoretic) proof of Roth’s theorem on arithmetic progressions, otherwise known as the k = 3 case of Szemeredi’s theorem. I’d like to start out by noting that there’s no shortage of good expositions on the topic; a quick Google search will turn up several. This series will differ from these expositions, however, in two key ways.
First, I’ll try to highlight the key ideas of the proof, rather than get bogged down in the calculations. Although, by the end of the series, we should have at least a sketch of a complete proof of Roth’s theorem, I want to make it easy to separate the real insights from the straightfoward calculational machinery. So I’ll likely present a high-level overview of the proof in the main body of these posts, with one or several appendices fleshing out the computations needed to ensure that the overview works.
Second, and more importantly, this is to be a piece of historical fiction. Although I don’t know how Roth came upon his original proof, he was a number theorist and an expert in Diophantine approximation, and was therefore familiar with things like Fourier analysis. I want to approach the problem from the perspective of a combinatorialist roughly contemporaneous with Roth, who’d be familiar with standard combinatorial methods but not with some of the more technical tools, and attempt to re-derive the proof from that viewpoint.
The real meat of the series will start this weekend (which is why this post is numbered 0), but since this is targeted toward a Generally Interested Lay Audience, I’d like to introduce a few topics which a layman might not be familiar with below the cut.
