I’m not sure how one returns to blogging after a two-year hiatus. Probably it should be with something more substantial than this post, which is about regularization in statistics and how I came to understand it. (This account comes from Vapnik’s Nature of Statistical Learning Theory, which I should have finished by now but I keep getting distracted by “classes” and “research” and also “television” and “movies.”)
One of the most basic questions I had when initially learning statistics was: Why do we need to regularize least-squares regression? The answer, I was told, was to prevent overfitting. But this wasn’t totally satisfactory; in particular, I never learned why overfitting is a phenomenon that should be expected to occur, or why ridge regression solves it.
The answer, it turns out, is right there on the Wikipedia page. Speaking very generally: we have some data, say  , and a class of functions
, and a class of functions  from which we want to draw our model. The goal is to minimize the distance between
from which we want to draw our model. The goal is to minimize the distance between 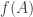 and
and  — if we can measure this distance, we have a functional
— if we can measure this distance, we have a functional  , which we seek to minimize.
, which we seek to minimize.
Now we want this functional to have the property that if the data of the response variable changes a tiny bit, then the at which our functional is minimized only changes a tiny bit. (Because we expect the data we measure to have some level of noise.) But this is not the case in general — actually, it’s not even the case when our functional is simply 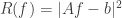 , i.e., when we’re doing least-squares linear regression. However, if we instead consider the related functional
, i.e., when we’re doing least-squares linear regression. However, if we instead consider the related functional 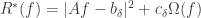 , then this does have the desired property — our problem is well-posed. And in general, we can regularize many implicit functionals in many paradigms in the same way.
, then this does have the desired property — our problem is well-posed. And in general, we can regularize many implicit functionals in many paradigms in the same way.
I also learned — though not from Vapnik — that you can derive ridge regression by putting a normal prior on the parameters in your model and then doing standard Bayesian things. But this doesn’t really explain why overfitting is a problem in the way the above account does — at least I don’t think so.
Question: Is there a natural correspondence between well-posed problems and “good” prior distributions on the parameters? (Meta-question: Is there a way to make that question more precise?)
(The title of this post is a Simpsons reference. Some things never change.)
 and girth at least 5 have
and girth at least 5 have 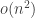 edges.
edges. has
has 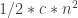 edges. Define the function
edges. Define the function 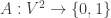 to be the “adjacency characteristic function.” Now, by Cauchy-Schwarz:
to be the “adjacency characteristic function.” Now, by Cauchy-Schwarz: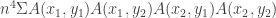

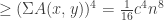 .
. fixed,
fixed, 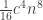 is unbounded as
is unbounded as  . But the first expression is
. But the first expression is 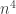 times the number of (possibly degenerate) 4-cycles in the graph; it’s easy to check that there are
times the number of (possibly degenerate) 4-cycles in the graph; it’s easy to check that there are 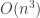 degenerate 4-cycles, so as n is unbounded our graph must contain a 4-cycle. QED
degenerate 4-cycles, so as n is unbounded our graph must contain a 4-cycle. QED .
. with root
with root 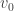 . Assign to each edge
. Assign to each edge  an element of the vector space
an element of the vector space 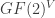 , obtained by setting 1s in the the coordinates corresponding to v and w and 0s elsewhere. I claim that these vectors are linearly independent; for suppose otherwise, and letthe vectors corresponding to
, obtained by setting 1s in the the coordinates corresponding to v and w and 0s elsewhere. I claim that these vectors are linearly independent; for suppose otherwise, and letthe vectors corresponding to 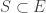 sum to 0. There is a natural “distance” function on E w/r/t
sum to 0. There is a natural “distance” function on E w/r/t  have maximal distance in S, and suppose WLOG that t is farther than s from
have maximal distance in S, and suppose WLOG that t is farther than s from  of them.
of them.